LIVE SITE
TOOLS
Java
Spring
Next.js
Python
Tailwind CSS
TEAM MEMBERSLarissa Troper
TIMELINEOct - Dec 2023
ACKNOWLEDGEMENTSThis project benefited from the guidance and insights provided by Professor Mark Smucker throughout the development of the search engine.
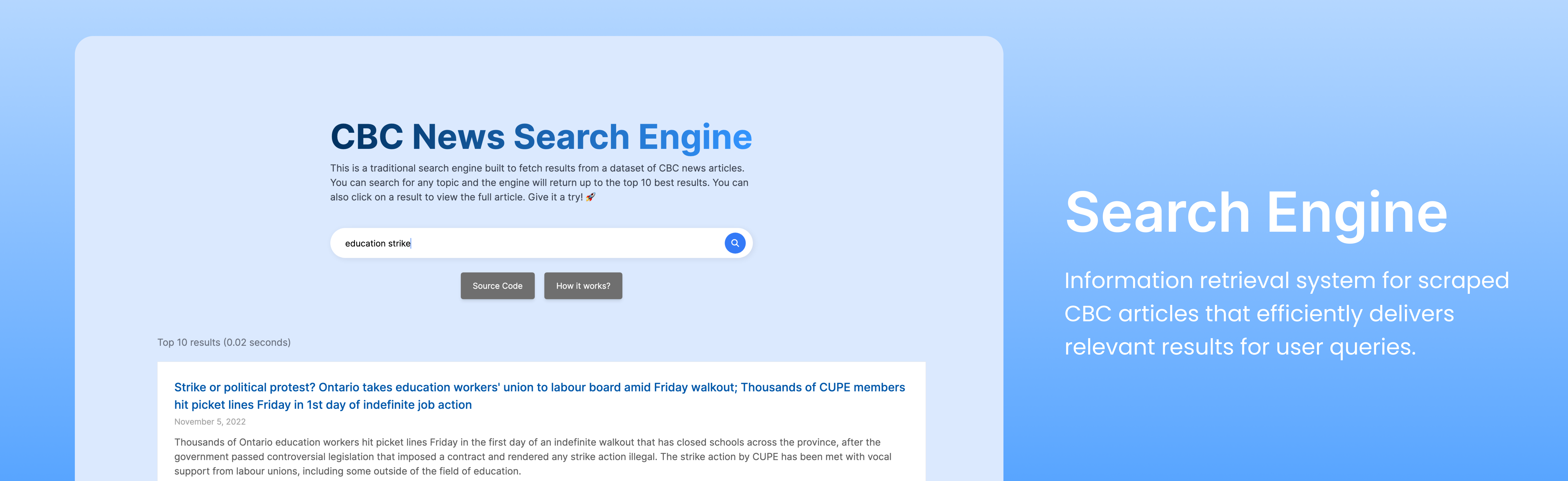
📋 CONTEXTProject Overview
This project was undertaken as part of the MSCI 541 course at the University of Waterloo. The objective was to develop a search engine command-line program using Java that accepts user query and returns top relevant results. The final product was capable of performing retrieval across a collection of 130,000+ LA Times articles, returning top search results within milliseconds.I expanded the project's functionality beyond its original scope by developing a data scraping script to obtain my own data (2000 CBC Articles), and utilizing Spring Boot API and Next.js interface to transform it into a dynamic web application.
⚙️ HOW IT WORKSSearch Engine BuildAn index engine was built to be able to process the scraped articles and extract relevant textual content. It tokenizes the text and constructs a lexicon. The engine then builds the inverted index, mapping terms to document identifiers and facilitating efficient query retrieval. Retrieval ProcessGiven a user query, the engine consults the inverted index to retrieve the list of candidate documents that contain some or all of the query terms.
Retrieval ProcessGiven a user query, the engine consults the inverted index to retrieve the list of candidate documents that contain some or all of the query terms.
The search engine then uses the BM25 scoring algorithm, a popular ranking function used in information retrieval, to assign a relevance score to each document based on the frequency of query terms within the document and other factors such as document length and term frequency within the document collection.
Retrieval ProcessGiven a user query, the engine consults the inverted index to retrieve the list of candidate documents that contain some or all of the query terms.The search engine then uses the BM25 scoring algorithm, a popular ranking function used in information retrieval, to assign a relevance score to each document based on the frequency of query terms within the document and other factors such as document length and term frequency within the document collection.